Single input images:







Learned generative 3D layouts:
Zero-shot Extrapolations to Varying Number of Instances:
SinLayout: uncovering spatial layout distribution from a single image
Motivation: When we, as humans, perceive a scene with various objects, we are able to parse their spatial arrangement and map it to an abstract mental representation, which enables us to imagine different variations. This ability is crucial for generating diverse and plausible 3D scenes with controllable spatial composition.
Abstract
What is a scene, conceptually? It can be decomposed into multiple objects, their spatial arrangement, and the background. While recent works have pushed the boundary on modeling 3D objects, the scene layout indicating how objects are arranged in 3D space remains under-explored. In this work, we build a generative model that learns the 3D scene layout distribution from a single 2D image, such as a photo of a parking lot containing several cars. We first retrieve the object geometry from segmented instances. Next, we build a permutation-equivariant model to generate layout parameters, which, combined with geometry, render scene images. We then leverage a patch-based discriminator on 2D images along with auxiliary losses to guide layout learning. Experiments demonstrate that our model successfully learns a wide range of layout distributions, each from a single Internet image. Our method achieves superior results on multiple downstream tasks, including extrapolating on number of instances and transferring learned layout to other objects.
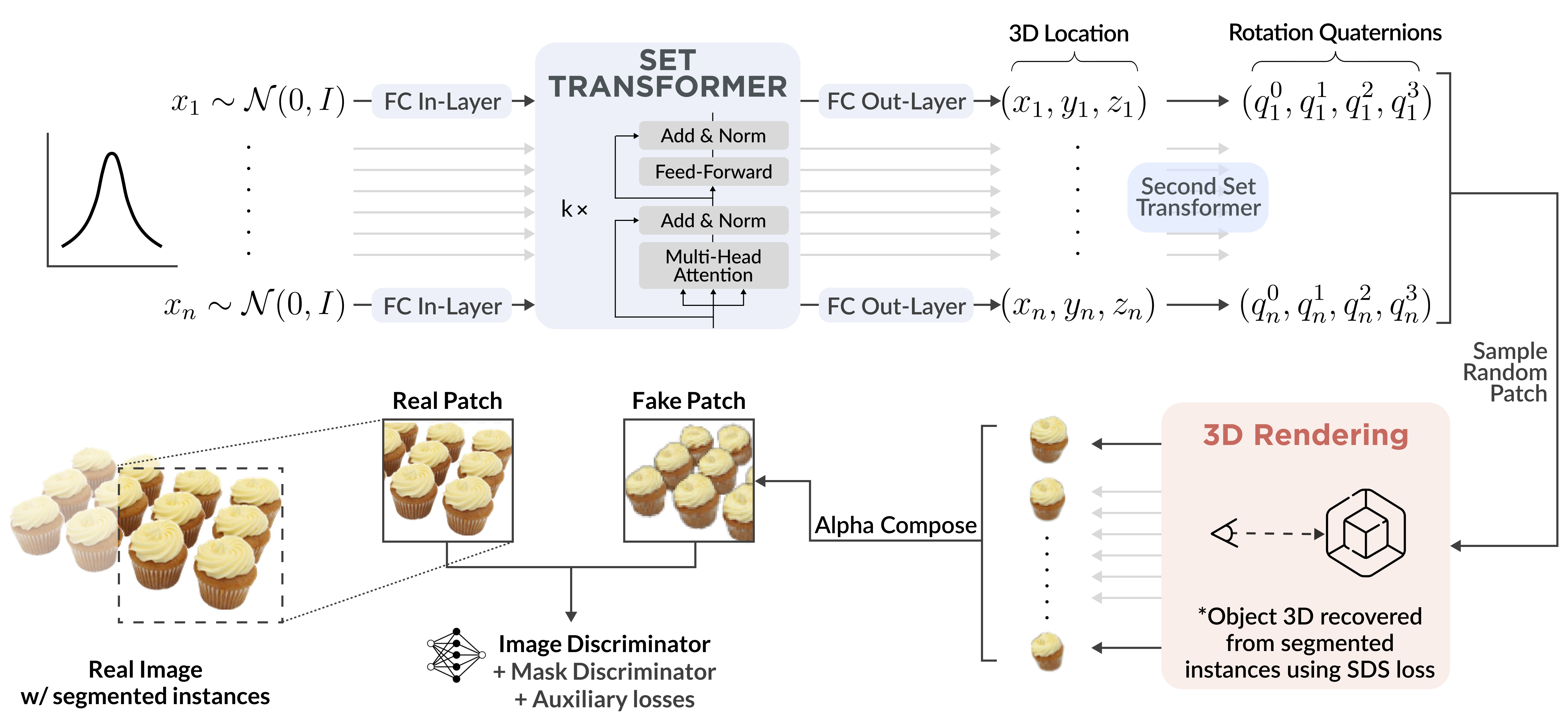
Pipeline Overview
Single-Image 3D Layout Generation
Diversity: Faithful Layout Generation with Variations
Input Image |
Generated Scene Layouts w/ Varying Latents |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Generalization: Extrapolating to Varying Number of Instances
Input Image |
Generated Scene Layouts w/ Varying Number of Instances |
|
|
|
|
|
|
|
16 instances |
8, 12, 20 instances |
|
|
|
|
12 instances |
6, 8, 16 instances |
|
|
|
|
14 instances |
6, 9, 16 instances |
|
|
|
|
11 instances |
6, 8, 16 instances |
|
|
|
|
19 instances |
6, 12, 32 instances |
|
|
|
|
20 instances |
12, 16, 24 instances |
|
|
|
|
33 instances |
10, 16, 40 instances |
Layout transfer to different instances
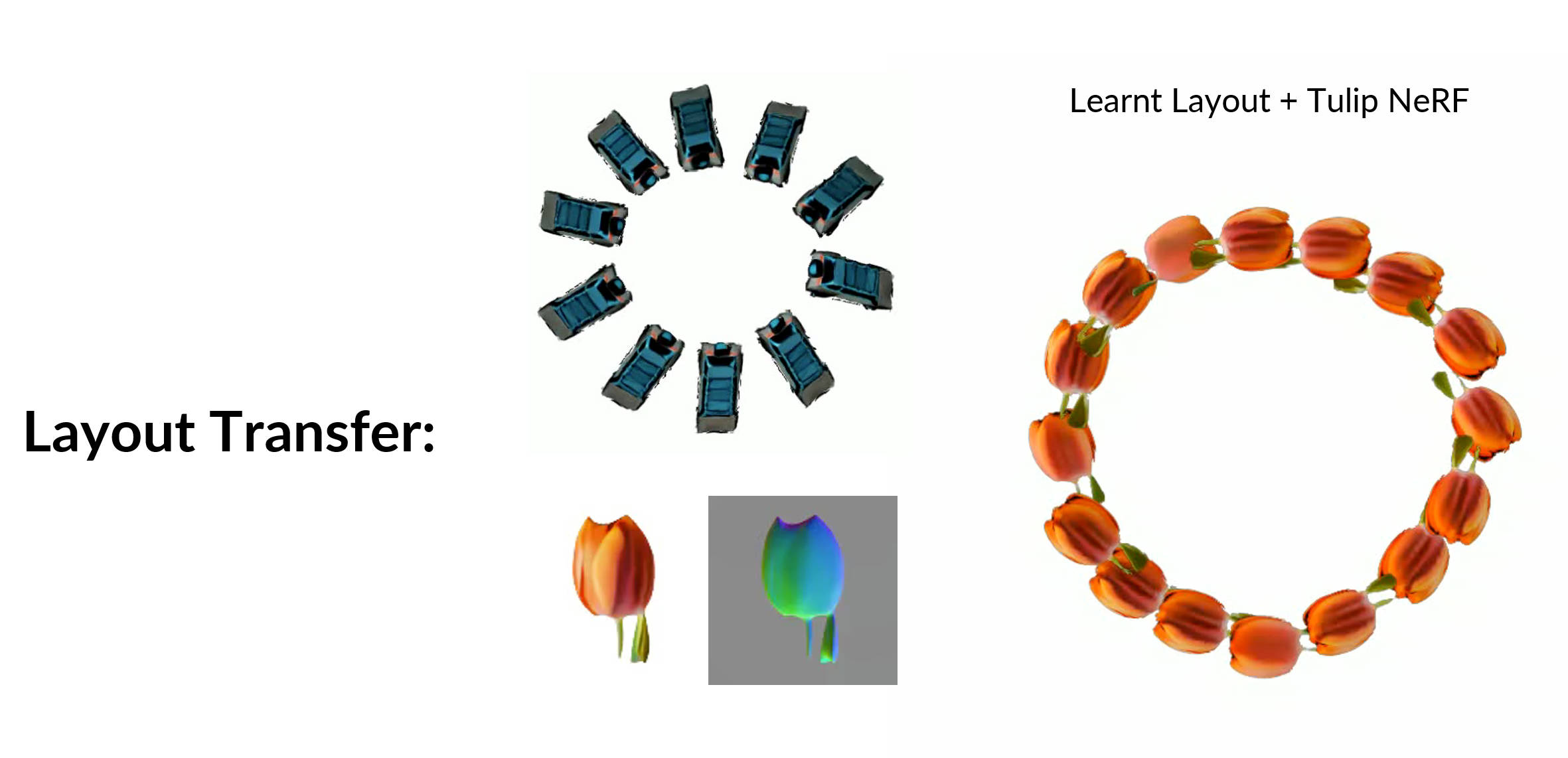
Transfering the layout learned from a circle of cars to the geometry of a tulip = a flower wreath
BibTeX
@article{sinlayout2024,
author = {Zhao, Linan and Yuan, Zeqing and Zhang, Yunzhi and Wu, Shangzhe and Wu, Jiajun},
title = {Learning Generative 3D Scene Layouts from a Single Image},
booktitle = {CVPR},
series = {AI for 3D Generation Workshop},
year = {2024},
}